
Amila Ferron
MS
Conversation Modeling
April 18, 2023
The latest state of the art Natural Language Processing research was announced last month when the list of accepted papers was released for the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL). Our lab has been incorporating the findings in guiding our research and drawing from the papers for weekly seminars. During these meetings we read a paper together, aloud, and share our thoughts as we go. Last week we selected a paper [1] titled “Estimating Overreporting in the Creditor Reporting System on Climate Adaptation Finance Using Text Classification and Bayesian Correction” from the 7th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, an event associated with EACL. This particular paper titled investigates overreporting of climate change adaptation measures taken by Germany, France, Japan, the United Kingdom, and the United States. I think it’s fair to say that we were all surprised by what the authors found. In this post, I’ll share some of the main points of the paper and what we discussed.
The Paris Agreement specified that developed countries should provide financial assistance to developing countries to support climate change adaptation and mitigation. Despite the widespread use of Rio Markers, a set of reporting tools developed by the Organisation for Economic Co-operation and Development, self-reported contributions do not always match up with the assistance actually rendered. Added to this lack of clarity, reporting agencies follow different reporting guidelines, further obscuring contribution measurement. Increasingly, small-scale investigations have found that this has led to overreporting of contributions. This is important because overreporting can keep vulnerable communities from receiving the aid they have been promised to help them survive the coming changes. This paper uses NLP methods to do a large-scale assessment of the overreporting.
The researchers in this study relied on records of each project contributing to climate change adaptation, along with the reported Rio Markers for the project. For simplicity, they focused on the top-five contributing countries. To give an idea of scale, there are about 1.5 million of these projects. It would take an incredible amount of resources to undertake a manual reassessment of all of these projects, so the authors created an automated assessment tool to estimate the true Rio Markers for each project. They then compared these estimates to the reported values to get an idea of the extent of overreporting.
When creating this tool, they first faced the data quality problem: Data is at the heart of every Machine Learning solution, and in this case the data isn’t perfect.
Two datasets were available for training, both based on studies that reassessed project Rio Markers. In both datasets, each project entry has a project description, the originally reported Rio Marker values, and the more accurate, reassessed Rio Marker values. In other words, these two previous studies addressed the problem of inaccurate reporting by providing manual reassessments. The first dataset is larger but less accurate; and the second, smaller but more reliable. The authors wanted to use the strengths of both of these previous studies to automatically reassess contribution reports of Rio Markers. In machine learning, a model needs to be trained on a dataset that is both large and accurate, but neither dataset is both of these at the same time. The authors overcame this by using the higher-quality dataset and the larger dataset in different steps of the process.
Taking advantage of its size, the bigger dataset was used to fine-tune a large language model. Large language models come pretrained on giant language datasets so their parameters contain information about a language that enables good performance on general tasks in that language. Fine-tuning exposes the model to more specific datasets and allows it to perform better on a task related to the datasets. After fine-tuning on the large reassessment dataset, the authors’ model could take project descriptions in English and, based on these descriptions, output predicted Rio Markers. They found that these predictions were more accurate than what had been originally reported for the projects. This first Rio Marker prediction language model was good, but was still not as reliable as the authors wanted.
To further improve prediction quality, the authors took advantage of the smaller but more reliable dataset. By comparing the fine-tuned model’s output for each project in the dataset to the actual Rio Markers for each project, the authors could see how close the model was getting to the true values. This step used Bayesian inference to create an adjustment that could be applied to each model output to give better results.
Now that the authors had developed a model that gave approximate results, and an adjustment that nudged the approximate results closer to the true values, they applied the workflow to the 1.5 million projects for the 5 biggest contributor countries. By comparing the reported Rio Markers with the adjusted results from the model, the extent and patterns of overreporting can be seen.
According to these findings, about one third of projects are inaccurately reported as relating to climate change adaptation. This may be intentional or unintentional, and convoluted reporting methods may be in part to blame, but the impact in any case is significant. The image below shows the results by country and year.
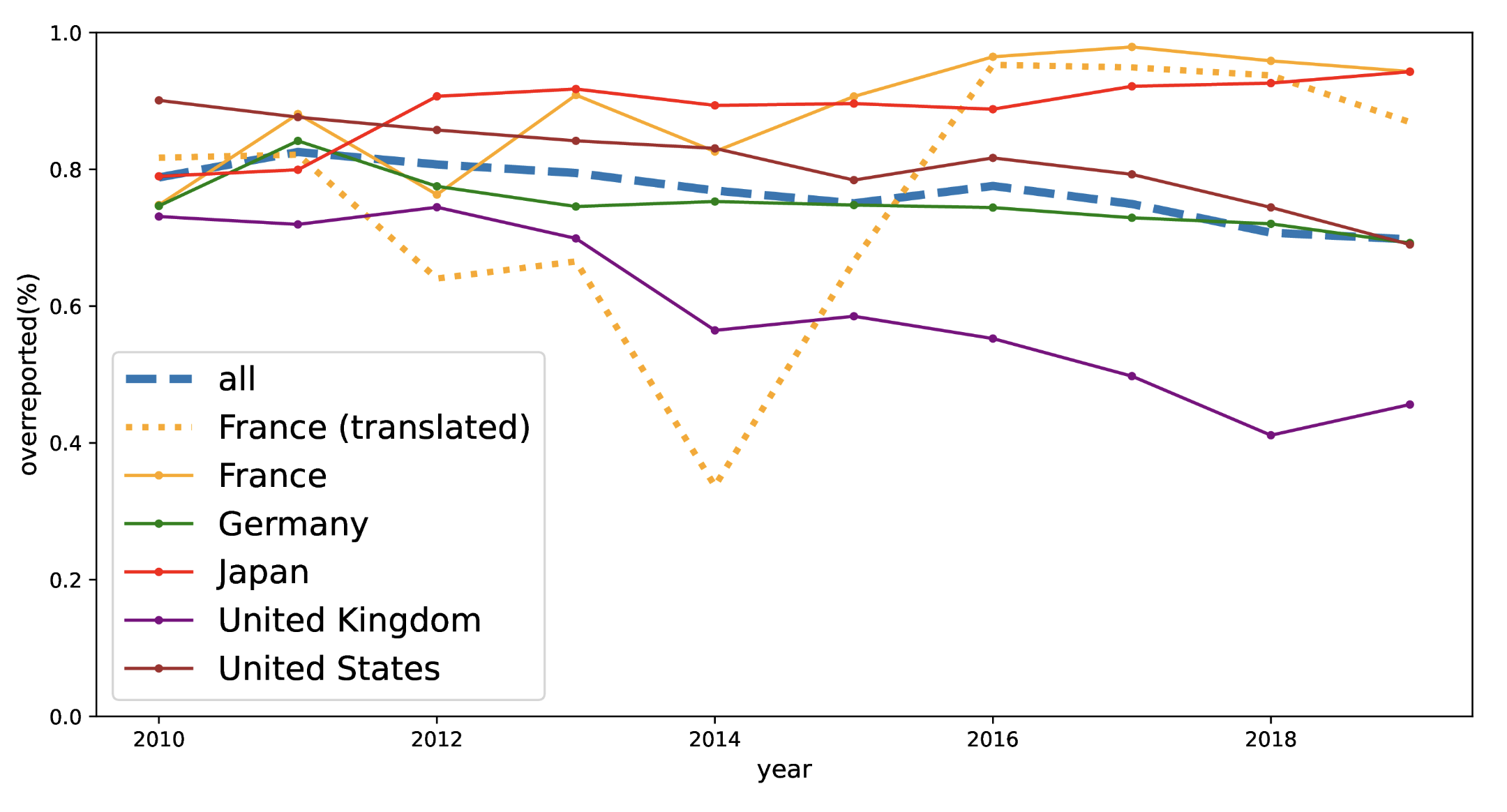
It’s important to note that the percentages shown for France might not be as accurate as for other countries. This is because reporting for France is mostly done in French, whereas all other countries report primarily in English. The need for translation – a problem also addressed with large language models – makes the results for France less certain.
It’s great to see how an imperfect dataset can be supplemented with a small set of higher-quality data through the use of Bayesian inference. During our discussions, it was mentioned that we don’t often see a combination of methods like this, but usually see the results from the model taken as is. This might be because as NLP researchers, we are more research-focused than application-focused and the real-world nature of this research means that a composition of methods was necessary.
We discussed the wealth of possibilities for cooperation between NLP and Social Sciences – for example, similar applications of NLP could have many uses for international NGOs that generate a lot of data. To me, this project stands out because it is the only one I have seen in this recently released set of state of the art papers that addresses a climate change-related issue. I hope our research community will publish more such work in upcoming top-tier conferences and workshops.
[1] Janos Borst,Thomas Wencker, Andreas Niekler. 2023. Estimating Overreporting in the Creditor Reporting System on Climate Adaptation Finance Using Text Classification and Bayesian Correction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 99–109, Association for Computational Linguistics.